Projeto Salifort Motors
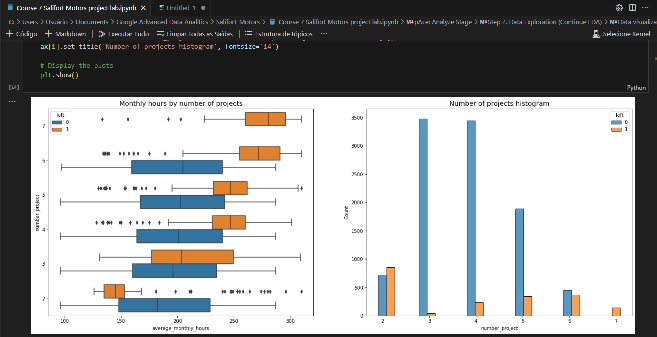
Esse modelo de floresta aleatória ajuda a prever se um funcionário deixará a empresa e identificar quais fatores são mais influentes. Esses insights podem ajudar o RH a tomar decisões para melhorar a retenção de funcionários.

Olá, Meu nome é Alessandro e sou estudante de ciência de dados na Univesp e desenvolvedor Full-Stack baseado no Brasil. Também sou membro ativo da comunidade brasileira GTC – Coursera, onde contribuo criando legendas para videoaulas. Tenho paixão por ciência de dados e programação e estou ansioso para colocar em prática tudo o que aprendi até agora.
Esse modelo de floresta aleatória ajuda a prever se um funcionário deixará a empresa e identificar quais fatores são mais influentes. Esses insights podem ajudar o RH a tomar decisões para melhorar a retenção de funcionários.
Os vídeos do TikTok recebem um grande número de relatos de usuários por muitos motivos diferentes. Nem todos os vídeos relatados podem passar por revisão por um moderador humano. Vídeos que fazem reivindicações (em vez de opiniões) são muito mais propensos a conter conteúdo que viola os termos de serviço da plataforma. O TikTok busca uma maneira de identificar vídeos que fazem alegações para priorizá-los para revisão.
Para o desenvolvimento do projeto, tem-se como objetivos específicos:
Determinar juntamente com a ONG as principais dificuldades enfrentadas com pet perdidos;
Desenvolver um software em linguagem JavaScript, framework Vue.js e que contenha um banco de dados PostgreSQL;
Testar a aceitação/performance do software proposto em conjunto com a ONG.
A Comissão de Táxi e Limusine da Cidade de Nova York busca uma maneira de utilizar os dados coletados na área da cidade de Nova York para prever o valor da tarifa para corridas de táxi. Usei duas arquiteturas de modelagem diferentes e comparei seus resultados. Infelizmente, nenhuma das duas abordagens apresentou previsões fortes.
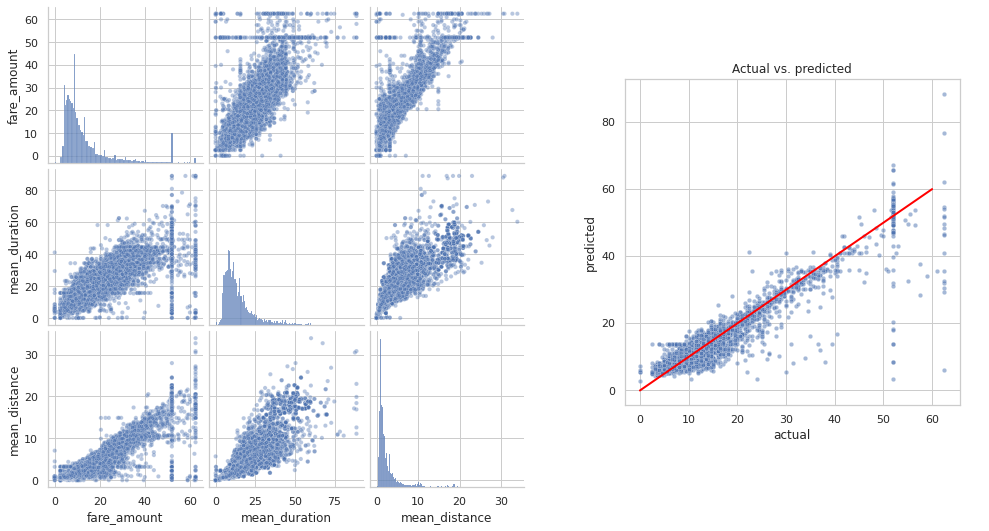
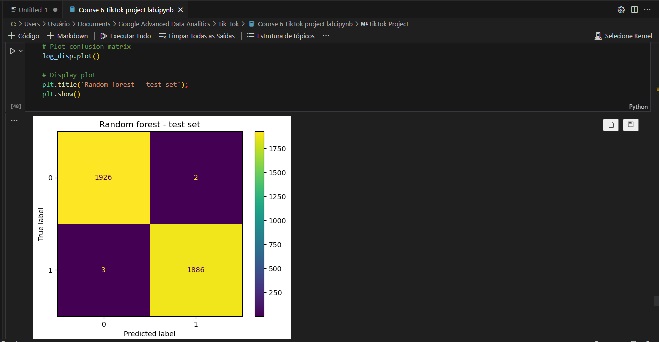
Para obter um modelo com maior poder preditivo, desenvolvi dois modelos diferentes para comparar os resultados: random forest e XGBoost. Os dados foram divididos em conjuntos de treinamento, validação e teste. Dividir os dados em três maneiras significa que há menos dados disponíveis para treinar o modelo do que dividir apenas duas maneiras. No entanto, realizar a seleção de modelo em um conjunto de validação separado permite testar o modelo campeão por si só no conjunto de teste, o que fornece uma estimativa melhor do desempenho futuro do que dividir os dados de duas maneiras e selecionar um modelo campeão por desempenho nos dados de teste.
(19) 993000487
Entre em contato